
如何提升爬虫开发效率?

在如今这个时代,做事不仅要好,还要快。 就拿爬虫开发来说,一般流程:
- 1、需求
- 2、抓包分析,逆向、加密分析等等
- 3、快速demo实现
- 4、测试各种反爬阈值和方式
一般来说以上比较有创造力和挑战的部分为第2步,枯燥的部分是第3步,耗时又挑战的的是第4步。
举个例子:
- 1、我们先打开fiddler开启抓包,以打开百度在首页输入fiddler这个关键字然后点击搜索为例:

- 2、我们用fiddler抓到如下结构的http raw 也就是原始请求
GET https://www.baidu.com/s?ie=utf-8&csq=1&pstg=20&mod=2&isbd=1&cqid=9c6a3121000073bd&istc=592&ver=0AptTQACOOLaje7bpKWCmO9W0LB-WyGVC93&chk=5ecfd530&isid=a343397400007821&ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=fiddler&fenlei=256&oq=fiddler&rsv_pq=a343397400007821&rsv_t=57b6eYcLSDA8QE1p50WhwfAEQ6DtQ2BjyjKulr6zpWMePo92BtEjK2Tabqw&rqlang=cn&rsv_dl=tb&rsv_enter=0&rsv_btype=t&bs=fiddler&f4s=1&_ck=3068.1.2.62.01837158203125.33.00523567199707.723.44&rsv_isid=31262_1420_31669_21113_31254_31673_31464_30824_26350&isnop=0&rsv_stat=-2&rsv_bp=1 HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Accept: */*
is_xhr: 1
X-Requested-With: XMLHttpRequest
is_referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=fiddler&fenlei=256&oq=fiddler&rsv_pq=9cbfb72f00001a0b&rsv_t=ca35LmlDAlpp4wImuJMR9NXBcQut4VBFAYJaDEjaUVL19Y2IA%2FL9haMBOS0&rqlang=cn&rsv_dl=tb&rsv_enter=0&rsv_btype=t
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=fiddler&fenlei=256&oq=fiddler&rsv_pq=a343397400007821&rsv_t=57b6eYcLSDA8QE1p50WhwfAEQ6DtQ2BjyjKulr6zpWMePo92BtEjK2Tabqw&rqlang=cn&rsv_dl=tb&rsv_enter=0&rsv_btype=t
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BAIDUID=0EC9FE012CA3639152BDD3AB753EE226:FG=1; BIDUPSID=0EC9FE012CA3639152BDD3AB753EE226; PSTM=1561388885; BD_UPN=12314353; BD_HOME=1; H_PS_PSSID=31262_1420_31669_21113_31254_31673_31464_30824_26350; delPer=0; BD_CK_SAM=1; PSINO=7; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_645EC=edcey0GmKppNfE6VNPwsilvMBjt9b1TPJA9ddNKrvMZHcUYM9O6D6VydSqg
3、以前都是手动将以上请求的写成python代码,耗时又枯燥,对于急性子来说太痛苦了:就写这个,我TM,三年之后又三年,三年之后又三年,就快十年了...
还好笔者几年前写了个工具叫pyheader,自动将以上http raw内容转换成python代码。
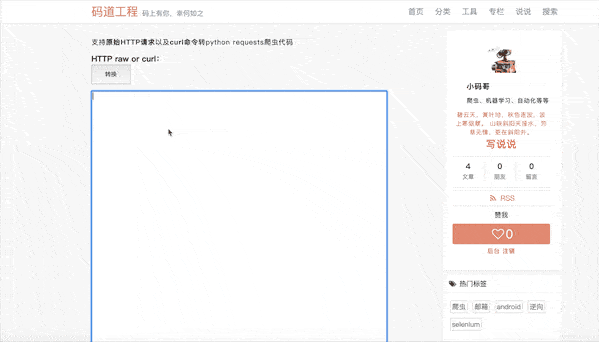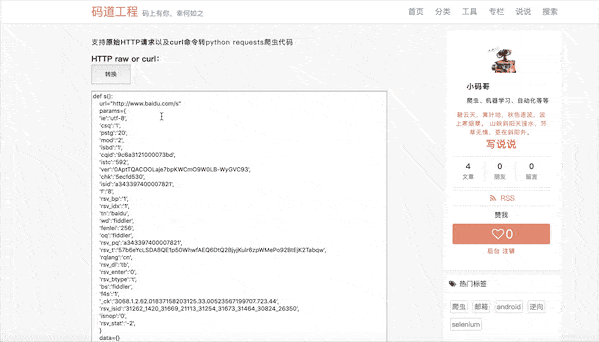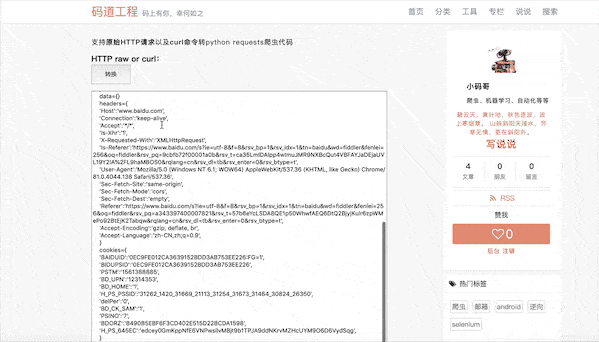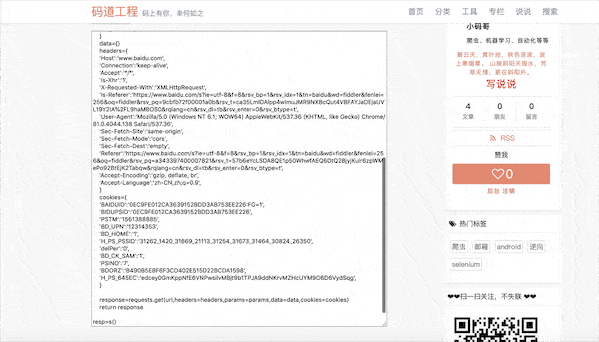
当然chrome下的copy curl字符命令也是支持的,你看:
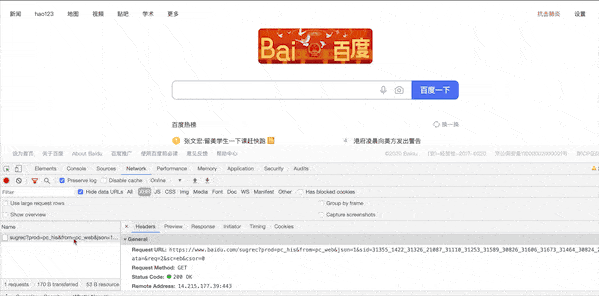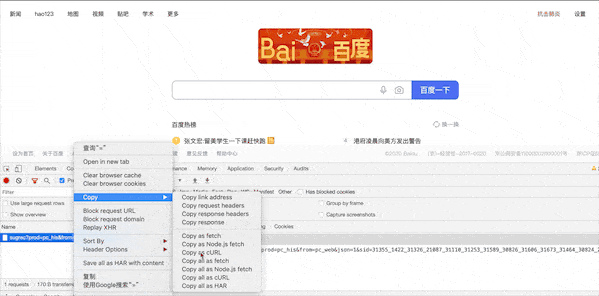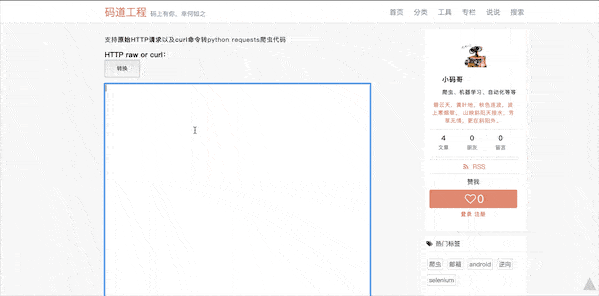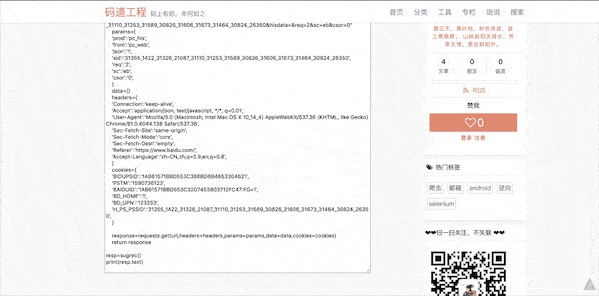
以前是离线版本,现在我已经把它放在我的个人在线网站上,大家随时使用:
https://www.tnt0.com/tool/pyheader
现在你可以说:以前我没得选,现在我选pyheader
防止失联,关注微信公众号:码道工程。


请先登陆 或 注册